いきなりまとめ
DeepBachモデルの特徴
- DeepBachは4つのレイヤーを持つ4つのモデルからなる
- それぞれのモデルは異なる音域を出力
- 過去と未来の情報を取り扱う2つのLSTMレイヤー
- 同時に発生する他の音を扱うレイヤー
- それらを統合し音を出力するレイヤー
- ユーザーの創意を取り入れ作曲することが可能
DeepBachのパフォーマンス
- 出来上がった曲に対して専門家を含め50%前後がバッハと回答
- 盗作の恐れも低い
Today I Learned
DeepBachモデルの詳細。
自動作曲されたサンプル。
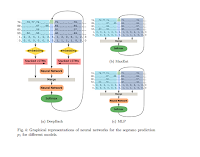
モデルの構造
入力データ=(V1,V2,V3,V4,S,F),
4つの音域に対応したMIDI音声(ソプラノ、アルト、テノール、バス)、ビート番号、fermatasの有無。
それぞれの音域ごとに4つのモデルを構築。
1つのモデルは4つのレイヤーからなる。
過去と未来の音を入力とする2つのembedding+LSTMレイヤー。
同時に発生する他の音を入力とするレイヤー。
それらをマージしピッチの確率を出力するレイヤー。
サンプルの生成
gibbs-samplingを使用。
4つの音に対応した長さLのリストをランダムに生成。
時間と音域をランダムに選び推定したモデルよりサンプリング。
利点はユーザーの好みを出力に反映できること。
たとえば、ある音域を固定、それ以外をサンプリング。
farmatasの調整。
音域ごとのサンプリングレンジの制限。
モデルの評価
人間に対するリスニングテストと盗作分析を実施。
リスニングテストでは3つのモデルを使用。
DeepBach、Maximum Entropy model、Multilayer Perceptron (MLP) model。
知覚テストでは同一のバッハのメロディーから2つのメロディーを生成し、どちらがよりバッハっぽいか聞いた 。
アンケートをもとにBradley-Terry modelによりスコアを推定。
DeepBachモデルは他のモデルより成績が良かった。

判別テストではメロディー1つを聞かせ、本物バッハか自動作曲か尋ねた。
DeepBachモデルは他のモデルより成績が良かった。
DeepBachを聞かせたところおよそ50%はバッハと判定。
バッハのむずさ考えればすげーよとのこと。
When presented a DeepBach-generated extract, around 50% of the voters would judge it as composed by Bach.
We consider this to be a good score knowing the complexity of Bach’s compositions and the facility to detect badly-sounding chords even for non musicians

盗作分析では生成されたメロディーがトレーニングに使ったメロディーと一致するその最大長を計測。
盗作の傾向はみられなかった。


0 件のコメント:
コメントを投稿